
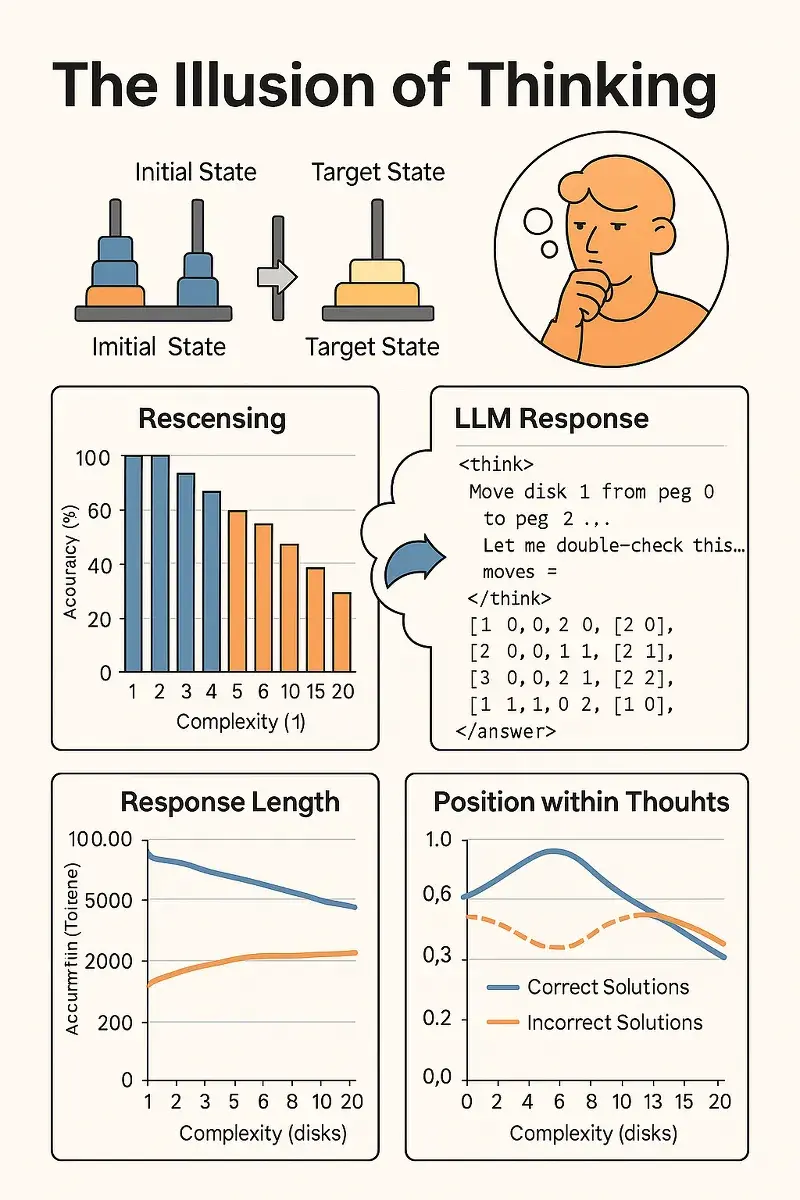
Este estudio examina el comportamiento de los modelos de lenguaje avanzados diseñados específicamente para el razonamiento, llamados Large Reasoning Models (LRMs), como Claude 3.7 Thinking y DeepSeek-R1. A través de experimentos sistemáticos en entornos de rompecabezas controlables (como la Torre de Hanoi, River Crossing, Checkers Jumping y Blocks World), los autores analizan cómo estos modelos procesan problemas de complejidad creciente.
Objetivos y metodología.
A diferencia de las evaluaciones tradicionales basadas en matemáticas o programación, los investigadores utilizan puzzles que permiten ajustar con precisión la complejidad del problema y estudiar tanto las respuestas finales como el proceso de razonamiento intermedio (Chain-of-Thought). Esto revela cómo «piensan» realmente estos modelos.
Principales hallazgos.
- Tres regímenes de rendimiento:
- En tareas simples, los modelos estándar (sin «pensamiento») superan a los LRMs en eficiencia.
- En tareas de complejidad media, los LRMs muestran ventajas gracias a su razonamiento paso a paso.
- En tareas complejas, ambos tipos de modelos colapsan, fallando por completo.
- Límites de escalado del razonamiento:
- Al aumentar la dificultad, los LRMs dedican más esfuerzo de razonamiento (tokens), pero solo hasta cierto punto. Luego, su esfuerzo disminuye, incluso si aún hay capacidad computacional disponible.
- Ineficiencias en el pensamiento:
- En problemas fáciles, los modelos hallan respuestas correctas temprano, pero siguen explorando soluciones incorrectas («sobrepensamiento»).
- En problemas medianos, las soluciones correctas emergen tras muchas intentos fallidos.
- En problemas difíciles, no se generan soluciones correctas en absoluto.
- Limitaciones estructurales:
- Los LRMs no logran seguir correctamente algoritmos explícitos ni verificar pasos lógicos, lo que sugiere debilidades fundamentales en su capacidad de razonamiento simbólico y secuencial.
Conclusión:
Los LRMs actuales presentan mejoras en tareas específicas, pero tienen límites claros al enfrentarse con problemas más complejos. Aunque incluyen mecanismos de reflexión y razonamiento, no desarrollan capacidades generalizables de solución de problemas. Estos hallazgos plantean dudas sobre la validez de las evaluaciones estándar y apuntan a la necesidad de nuevos enfoques para avanzar en la inteligencia artificial realmente razonadora.
Para ver el documento completo visite: ml-site.cdn-apple.com/papers/the-illusion-of-thinking.pdf


