

No es el tamaño de tu acelerador, es cómo lo usas.
La startup de edición genética Metagenomi ha recurrido a los aceleradores Inferentia 2 de AWS para acelerar el descubrimiento de terapias que podrían salvar vidas, y afirmó que sus esfuerzos costaron un 56% menos de lo que habrían invertido utilizando GPU de Nvidia.
Fundada en 2018, Metagenomi utiliza un enfoque ganador del Premio Nobel, desarrollado por Jennifer Doudna y Emmanuelle Charpentier, llamado CRISPR, que permite la edición dirigida de secuencias genéticas.
«La edición genética es una nueva modalidad terapéutica destinada a tratar enfermedades abordando la causa a nivel genético. Por lo tanto, en lugar de tratar los síntomas, se busca una cura», declaró Chris Brown, vicepresidente de descubrimiento de Metagenomi, a El Reg.
Estas terapias se basan en la identificación de enzimas (esencialmente catalizadores biológicos que facilitan las reacciones químicas) que pueden unirse a las secuencias de ARN que las guían a su destino, cortar el ADN objetivo en el punto correcto y, fundamentalmente, adaptarse al mecanismo de administración elegido.
Para encontrar estas enzimas, la startup utiliza un tipo de IA generativa conocida como modelos de lenguaje proteico (PLM), como Progen2, para generar rápidamente millones de candidatos potenciales.
«Se trata de encontrar esa única opción entre un millón. Así que, si tienes acceso al doble, duplicas tus posibilidades de obtener un producto final», afirmó Brown.
Desarrollado por investigadores de las universidades de Salesforce, Johns Hopkins y Columbia en 2022, Progen2 es un modelo de transformador autorregresivo similar a GPT-2. Pero en lugar de generar cadenas de texto, sintetiza nuevas secuencias de proteínas.
Con un peso aproximado de 800 millones de parámetros para el modelo base, Progen2 es diminuto en comparación con los grandes modelos de lenguaje modernos como GPT-4 o DeepSeek R1, lo que significa que su ejecución no requiere grandes cantidades de memoria de alto ancho de banda. Para la prueba, Metagenomi comparó el acelerador Inferentia 2 de AWS con el L40S de Nvidia, que la startup biotecnológica utilizaba previamente para ejecutar Progen2.
Lanzado en 2023, Inferentia 2 es (como su nombre indica) un acelerador optimizado para inferencias, con 32 GB de memoria de alta densidad (HBM), 820 GB/s de ancho de banda de memoria y 190 teraFLOPS de rendimiento de 16 bits.
En comparación, el L40S, basado en la arquitectura de GPU Ada Lovelace de la generación anterior de Nvidia, cuenta con 48 GB de GDDR6, lo que equivale a 864 GB/s de ancho de banda de memoria y 362 teraFLOPS con precisión de 16 bits.
Sin embargo, si bien el L40S supera a Inferentia 2 en teoría, Amazon afirma que su chip puede realizar la misma tarea de forma más económica al aprovechar su canalización de procesamiento por lotes, AWS Batch, y las instancias puntuales.
Las instancias puntuales suelen tener un coste aproximadamente un 70% inferior al de las instancias bajo demanda. Dado que los flujos de trabajo que optimizaban podían programarse en torno a las instancias puntuales utilizando AWS Batch, esto simplificó enormemente estas implementaciones y les permitió programar diferentes tipos de experimentación para que se ejecutaran las 24 horas del día, declaró Kamran Khan, jefe de desarrollo comercial del área de aprendizaje automático del equipo Annapurna Labs de AWS.
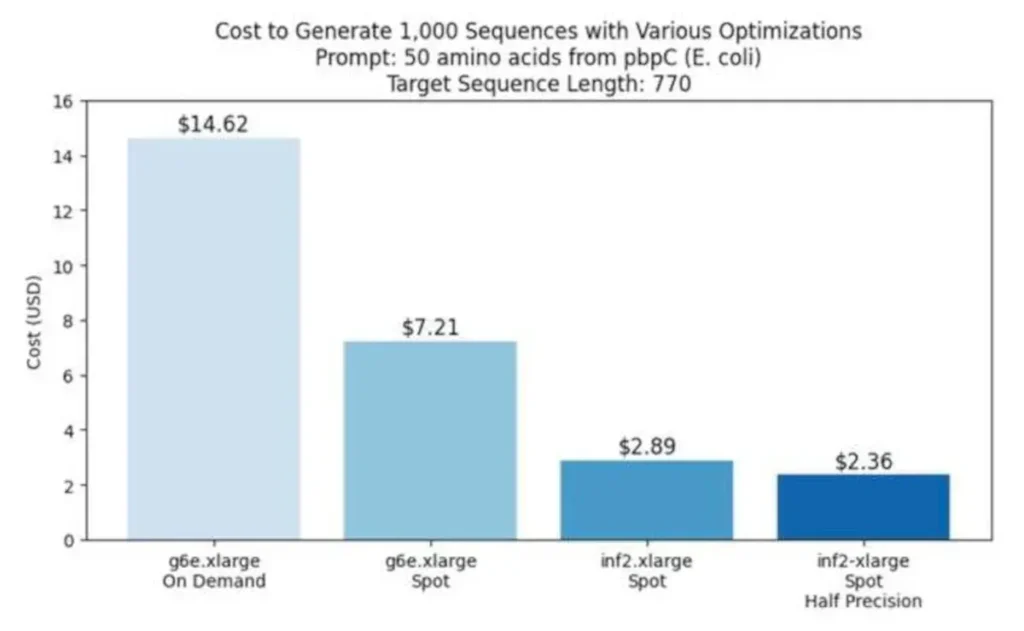
Gran parte del ahorro derivado del uso de Inferentia se debió a una mayor disponibilidad. El gigante de la nube afirma que la tasa de interrupción de su chip de desarrollo propio es de aproximadamente el 5%, en comparación con el 20% de las instancias puntuales basadas en L40S de Nvidia. En teoría, esto significa que solo uno de cada 20 lotes de generación de proteínas de Metagenomi debería interrumpirse, frente a uno de cada cinco del acelerador de Nvidia.
Para Brown, el menor costo operativo de Inferentia se traduce directamente en más investigación científica, lo que aumenta la probabilidad de descubrir enzimas capaces de abordar diferentes dolencias.
«Tomamos un problema que habría sido un proyecto para todo el año y, en cambio, lo convertimos en algo que mi equipo puede abordar varias veces al día o a la semana», dijo Brown.
La colaboración también destaca que, para las cargas de trabajo de IA que no son interactivas, un hardware más rápido no siempre es mejor: los aceleradores más antiguos y con grandes descuentos pueden ofrecer una mejor relación calidad-precio.


