Qué cambian realmente las hiperconexiones con restricciones de variedad.
Resumen:
- Problema: Las hiperconexiones (HC) originales de ByteDance mostraron potencial, pero se volvieron inestables a gran escala.
- Solución: mHC restringe las matrices residuales a variedades doblemente estocásticas, lo que previene las explosiones de gradiente.
- Ingeniería: Kernels personalizados, recálculo de activación y flujos de cálculo dedicados para el paralelismo de pipeline.
- Resultado: Entrenamiento estable a gran escala sin sobrecarga computacional.
- Lo realmente innovador: No son las matemáticas, sino la capacidad de rediseñar toda la pila de entrenamiento en torno a ideas experimentales.
Antecedentes: Qué problema intentaba resolver HC.
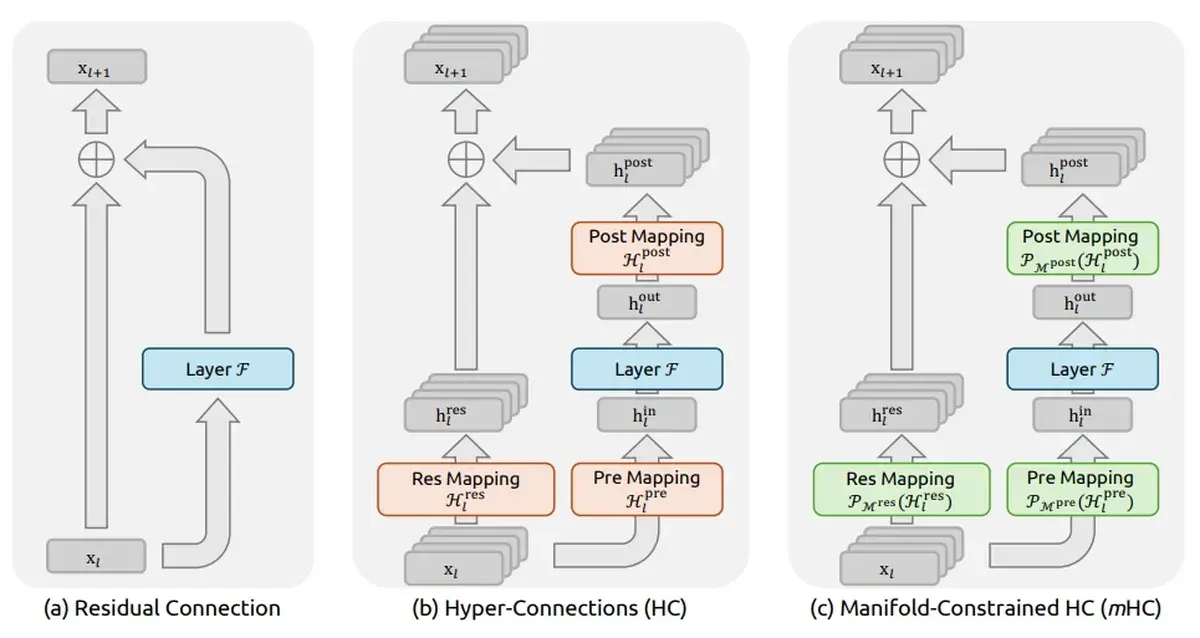
Las redes neuronales profundas utilizan conexiones residuales: las «conexiones de salto» que permiten que los gradientes fluyan a través de la red. La formulación estándar es simple: salida = F(x) + x.
Pero esto crea un problema: a medida que los modelos se vuelven más profundos, las capas se vuelven redundantes. Los estudios de interpretabilidad muestran que las características ocultas en las capas más profundas se vuelven muy similares, lo que disminuye la contribución de las capas adicionales. Esto se llama colapso de representación.
El artículo sobre hiperconexiones (HC) de ByteDance propuso una solución: hacer que la función residual sea aprendible. En lugar de conexiones de salto fijas, permitir que el modelo aprenda «conexiones de profundidad y de ancho» óptimas que puedan crear configuraciones de capas que superen las configuraciones secuenciales tradicionales.
Los resultados fueron prometedores. En un pequeño Olmo-MoE, HC convergió 1,8 veces más rápido y mostró una mejora de 6 puntos en ARC-Challenge. La interpretabilidad de las capas confirmó que las variantes de HC exhibieron una similitud significativamente menor entre las características.
Por qué HC falla a gran escala.
Aquí es donde se pone interesante. DeepSeek intentó escalar HC a modelos de vanguardia y se encontró con dos problemas principales:
- Inestabilidad del entrenamiento: «A medida que aumenta la escala del entrenamiento, HC introduce riesgos potenciales de inestabilidad». Específicamente, observaron aumentos inesperados de la pérdida alrededor del paso 12.000, altamente correlacionados con la inestabilidad de la norma del gradiente.
- Eficiencia de la memoria: «La eficiencia del hardware con respecto a los costos de acceso a la memoria para el flujo residual ampliado no se aborda en el diseño original».
La inestabilidad es el problema principal. No se puede entrenar un modelo de vanguardia si explota aleatoriamente en el paso 12.000.
Qué cambia mHC: La restricción de variedad.
La clave de DeepSeek: la inestabilidad proviene de que las matrices residuales se desvían del mapeo de identidad. Cuando las conexiones aprendidas se desvían demasiado, los gradientes explotan.
La solución es elegante: restringir las matrices de conexión residual para que permanezcan dentro de una variedad de matrices doblemente estocásticas. Una matriz doblemente estocástica tiene filas y columnas que suman 1; es una «permutación suave» que no se aleja demasiado de la identidad.
Esto es lo que se denomina «Restricción de Variedad» en mHC. Las matemáticas (secciones 4.1 y 4.2 del artículo) son elegantes, pero la idea clave es simple: no permitir que las conexiones aprendidas se descontrolen.
La verdadera proeza: Ingeniería a escala.
Las matemáticas son interesantes, pero el núcleo del artículo se encuentra en la sección 4.3: «Diseño de entrenamiento eficiente». Aquí es donde DeepSeek demuestra lo que los convierte en un laboratorio de vanguardia.
1. Kernels personalizados.
Desarrollaron tres nuevos kernels de mHC que «emplean estrategias de precisión mixta para maximizar la precisión numérica sin comprometer la velocidad, y fusionan múltiples operaciones con acceso a memoria compartida en kernels de computación unificados para reducir los cuellos de botella del ancho de banda de la memoria».
2. Recálculo de activaciones.
Para gestionar la sobrecarga de memoria, «descartan las activaciones intermedias de los kernels de mHC después del paso hacia adelante y las recalculan sobre la marcha en el paso hacia atrás». Un clásico compromiso entre tiempo y memoria, pero implementado a nivel de kernel.
3. Adaptación del paralelismo de pipeline.
mHC incurre en una latencia de comunicación sustancial entre las etapas del pipeline. Su solución: «ejecutar los kernels Fpost,res de las capas MLP (es decir, FFN) en un flujo de computación dedicado de alta prioridad» para evitar bloquear el flujo de comunicación.
Por qué esto es importante.
La verdadera proeza de este artículo no es demostrar que las hiperconexiones pueden funcionar a escala, sino demostrar:
«Tenemos la capacidad interna para rediseñar completamente el entorno de entrenamiento en todas sus dimensiones (kernels, gestión de memoria, comunicación entre nodos) en torno a ideas de investigación altamente experimentales».
Eso es lo que te convierte en un laboratorio de vanguardia.
La mayoría de las organizaciones pueden leer un artículo e implementar el algoritmo. Pocas pueden reescribir toda su infraestructura de entrenamiento para que una idea experimental funcione a escala. Esta es la ventaja competitiva.
Implicaciones para los profesionales.
Si está entrenando modelos y considerando mHC:
No utilice HC estándar a escala. La inestabilidad es real.
La restricción de variedad es esencial. Sin ella, espere picos de pérdida alrededor de los 10.000-15.000 pasos.
La sobrecarga de memoria es manejable con el recálculo de activaciones, pero necesita control a nivel de kernel.
El paralelismo de canalización requiere un manejo especial. Se necesitan flujos de cálculo dedicados para las operaciones de mHC.
Preguntas frecuentes:
¿Qué es DeepSeek mHC?.
mHC (Manifold-Constrained Hyper-Connections) es la solución de DeepSeek para escalar las hiperconexiones a modelos de vanguardia. Restringe las matrices residuales entrenables a variedades doblemente estocásticas para evitar la inestabilidad durante el entrenamiento.
¿Por qué fallaron las hiperconexiones originales a gran escala?.
Las hiperconexiones originales presentaban riesgos potenciales de inestabilidad a medida que aumentaba la escala del entrenamiento, con picos inesperados de pérdida alrededor de los 12.000 pasos, correlacionados con la inestabilidad de la norma del gradiente.
¿Necesito kernels personalizados para usar mHC?.
Para su uso en producción a gran escala, sí. Las optimizaciones de memoria y computación requieren control a nivel de kernel. Para investigación o experimentación, una implementación básica puede funcionar, pero se espera un mayor consumo de memoria.