

Amazon Web Services (AWS) está desarrollando un enorme clúster de supercomputación con cientos de miles de aceleradores que promete dar ventaja a sus colegas de Anthropic, dedicados a la construcción de modelos, en la carrera armamentística de la IA.
El sistema, denominado Proyecto Rainier, se pondrá en marcha a finales de este año con computación en múltiples ubicaciones en Estados Unidos. Gadi Hutt, director de ingeniería de producto y cliente de Annapurna Labs de Amazon, declaró a El Reg que una de las ubicaciones en Indiana albergará treinta centros de datos de 18.000 metros cuadrados cada uno. Recientemente se informó que esta instalación por sí sola consume más de 2,2 gigavatios de energía.
Pero a diferencia de Stargate de OpenAI, Collusus de xAI o el propio Proyecto Ceiba de AWS, este sistema no utiliza GPU. En cambio, el Proyecto Rainier representará el mayor despliegue de silicio de IA de Annapurna de Amazon hasta la fecha.
«Esta es la primera vez que construimos un clúster de entrenamiento a tan gran escala que permitirá a un cliente, en este caso Anthropic, entrenar un único modelo en toda esa infraestructura», declaró Hutt. «La escala no tiene precedentes».
Amazon, por si lo han olvidado, es uno de los principales patrocinadores de Anthropic, habiendo invertido ya 8.000 millones de dólares en el rival de OpenAI.
Amazon no está lista para revelar el alcance total del proyecto, y dado que se trata de un proyecto multisitio similar a Stargate, en lugar de una fábrica de IA única como Colossus, el Proyecto Rainier podría no tener límites máximos. Y todos los planes asumen que las condiciones económicas que impulsaron el auge de la IA no se desvanezcan.
Sin embargo, nos dicen que Anthropic ya ha conseguido hacerse con una pequeña parte de la computación del sistema.
Si bien no sabemos cuántos chips Trainium o centros de datos impulsarán finalmente el Proyecto Rainier, y probablemente no lo sabremos hasta re:Invent en noviembre, tenemos una idea bastante clara de cómo será. Aquí está todo lo que sabemos sobre el Proyecto Rainier hasta ahora.
La unidad básica de computación

El núcleo del Proyecto Rainier es el acelerador Trainium2 de Annapurna Lab, que se lanzó en la web en diciembre.
A pesar de lo que su nombre pueda sugerir, el chip puede utilizarse tanto para cargas de trabajo de entrenamiento como de inferencia, lo que resultará muy útil para los clientes que utilizan aprendizaje por refuerzo (RL), como vimos con DeepSeek R1 y o1 de OpenAI, para dotar a sus modelos de capacidades de razonamiento.
«El RL, como carga de trabajo, incorpora mucha inferencia, ya que necesitamos verificar los resultados durante las etapas del entrenamiento», afirmó Hutt.
El chip cuenta con un par de matrices de cómputo de 5 nm unidas mediante la tecnología de encapsulado chip-on-wafer-on-susstrate (CoWoS) de TSMC, alimentadas por cuatro pilas HBM. En conjunto, cada acelerador Trainium2 ofrece 1,3 petaFLOPS de rendimiento FP8 denso, 96 GB de HBM y 2,9 TB/s de ancho de banda de memoria.
Por sí solo, el chip no parece muy competitivo. El B200 de Nvidia, por ejemplo, presume de 4,5 petaFLOPS de FP8 denso, 192 GB de HBM3e y 8 TB/s de ancho de banda de memoria.
La compatibilidad con 4x de dispersión, que puede acelerar drásticamente las cargas de trabajo de entrenamiento de IA, ayuda a Tranium2 a reducir la diferencia, elevando el rendimiento de FP8 a 5,2 petaFLOPS, pero aún se queda por detrás del B200, con 9 petaFLOPS de computación dispersa con la misma precisión.
Trn2.
Si bien Tranium2 puede parecer un poco débil en una comparación chip a chip con los aceleradores más recientes de Nvidia, eso no lo explica todo.
A diferencia de las GPU de las series H100 y H200, la B200 de Nvidia solo está disponible en formato HGX de ocho vías. De igual forma, la configuración mínima de AWS para Trainium2, a la que denomina instancias Trn2, incluye 16 aceleradores.

«Cuando se trata de clústeres grandes, lo que proporciona un solo chip es menos importante, sino más bien lo que se denomina ‘buena puesta en funcionamiento'», explica Hutt. «¿Cuál es su buen rendimiento de entrenamiento, considerando también el tiempo de inactividad?. No veo mucha discusión al respecto en la industria, pero esta es la métrica que los clientes buscan».
En comparación con los sistemas HGX B200 de Nvidia, la diferencia de rendimiento es mucho menor. Los componentes basados en Blackwell aún tienen ventaja en cuanto a ancho de banda de memoria y computación densa en FP8, indicadores clave del rendimiento de inferencia.
Para cargas de trabajo de entrenamiento, las instancias Trn2 de Amazon sí tienen cierta ventaja, ya que, al menos en teoría, ofrecen un mayor rendimiento en coma flotante dispersa en FP8. Si bien los chips Blackwell de Nvidia admiten una precisión de coma flotante de 4 bits, aún no hemos visto a nadie entrenar un modelo con esa precisión. El cómputo disperso es más útil cuando se espera que grandes volúmenes de datos tengan valores cero. Por lo tanto, la dispersión no suele ser muy útil para la inferencia, pero puede marcar una gran diferencia en el entrenamiento.
Dicho esto, aquí presentamos un breve análisis de cómo se compara Blackwell B200 de Nvidia con las instancias Trn2 de AWS:
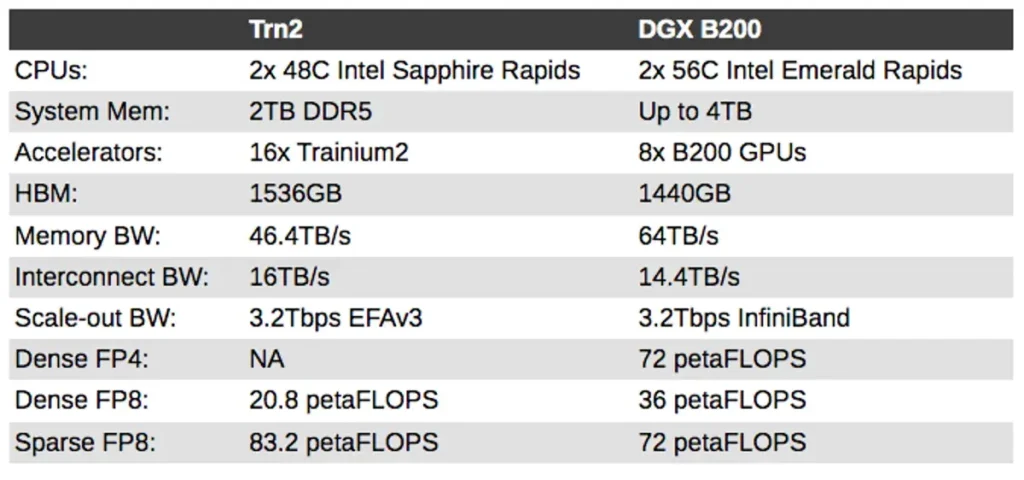
Al observar más de cerca cada clúster Trn2, se observa que los chips están distribuidos en ocho blades de cómputo (dos Trainium2 cada uno), gestionados por un par de CPU x86 de Intel. En este sentido, la arquitectura recuerda en cierta medida a los sistemas de rack NVL72 de Nvidia.
Sin embargo, en lugar de una topología conmutada de todos a todos, como la del NVL72, los chips de cada clúster Trn2 están conectados en un toro 2D 4×4 mediante la interconexión NeuronLink v3 de alta velocidad de AWS. Esta topología elimina la necesidad de conmutación de alta velocidad, pero añade uno o dos saltos adicionales de latencia para la comunicación entre chips.
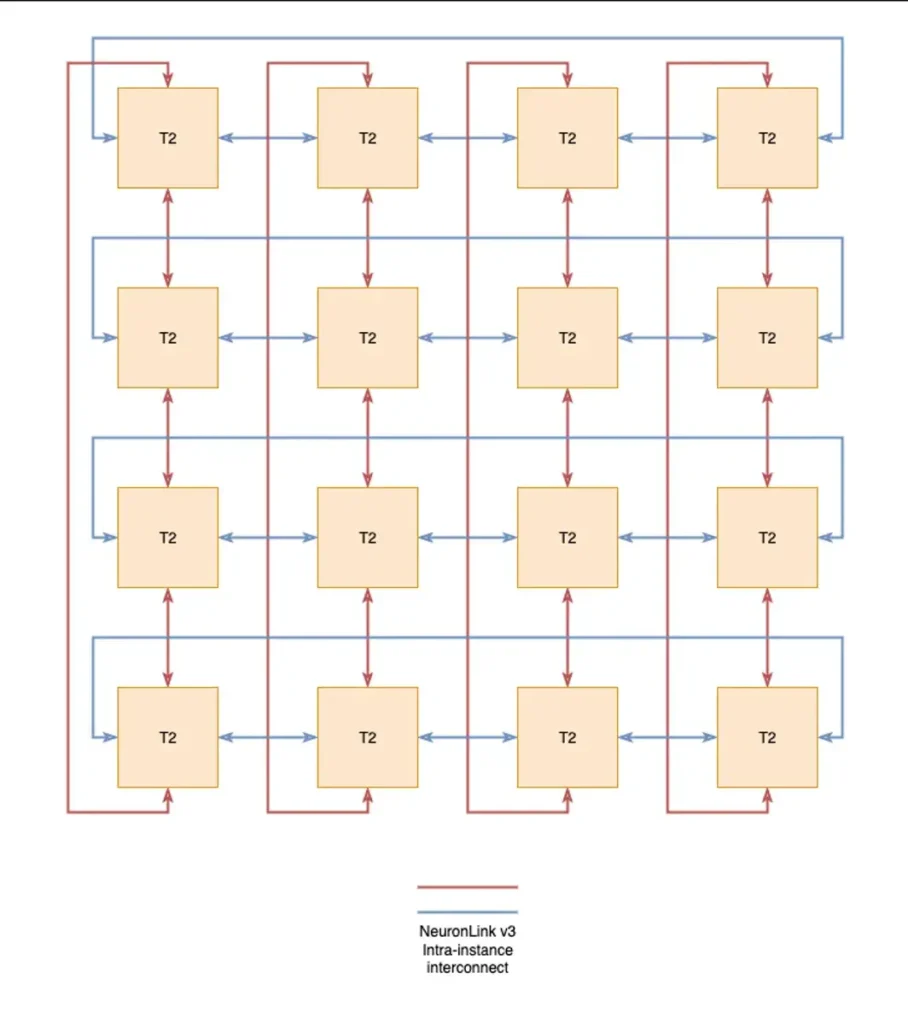
Esta interconexión entre instancias, similar a NVLink de Nvidia o InfiniFabric de AMD, proporciona 1 TB/s de ancho de banda de chip a chip a cada acelerador del clúster Trn2.
Alcanzando la escala de rack.

Cuatro sistemas Trn2 pueden integrarse mediante NeuronLink para ampliar el dominio de cómputo de 16 a 64 chips, en una configuración que AWS denomina UltraServer.
Esto se logra apilando los sistemas Trn2 uno sobre otro para formar un toro tridimensional, que, si le cuesta visualizarlo, se parece a esto:
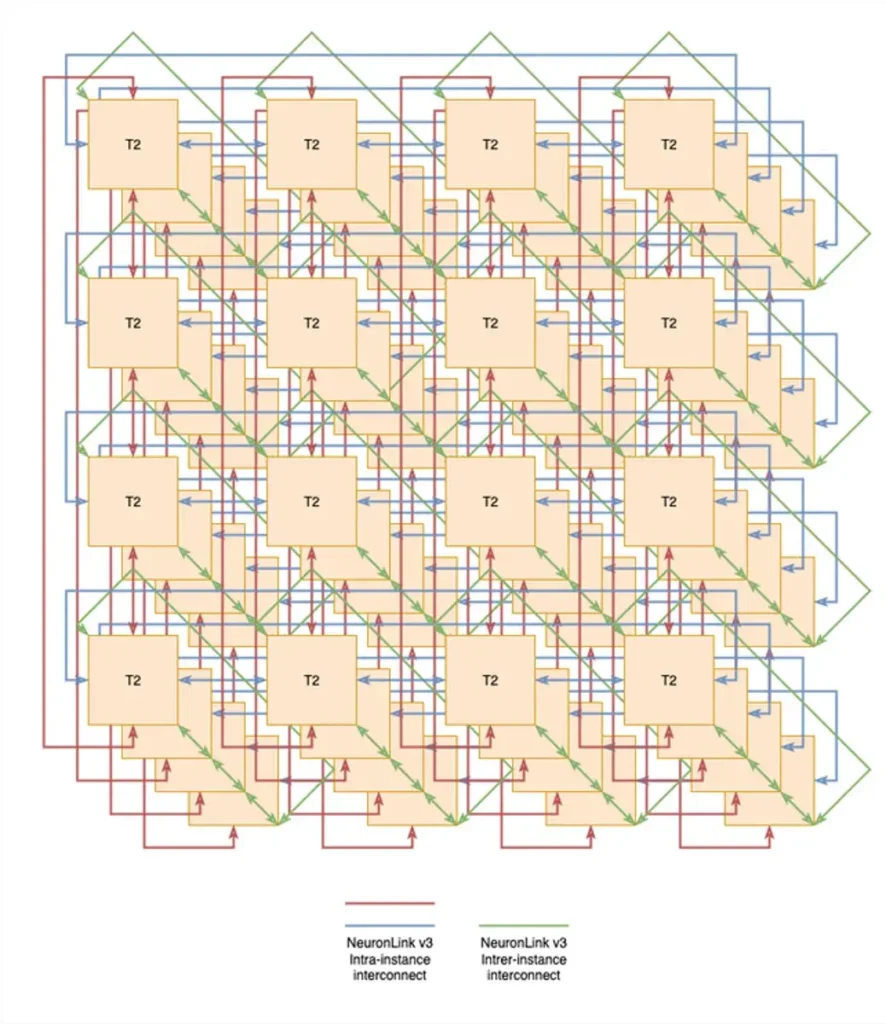
Según la documentación de Amazon, el ancho de banda entre instancias que proporciona NeuronLink entre las instancias Trn2 es bastante menor, con 256 GB/s de ancho de banda por chip.
Una vez más, esta malla de chip a chip se logra sin conmutadores, lo que ofrece la ventaja de un menor consumo de energía. Esto, junto con la menor densidad de cómputo que ofrece la distribución del sistema en dos racks, ha permitido a AWS prescindir de la refrigeración por aire, algo que no puede decirse de los sistemas NVL72 que está implementando como parte del Proyecto Ceiba.
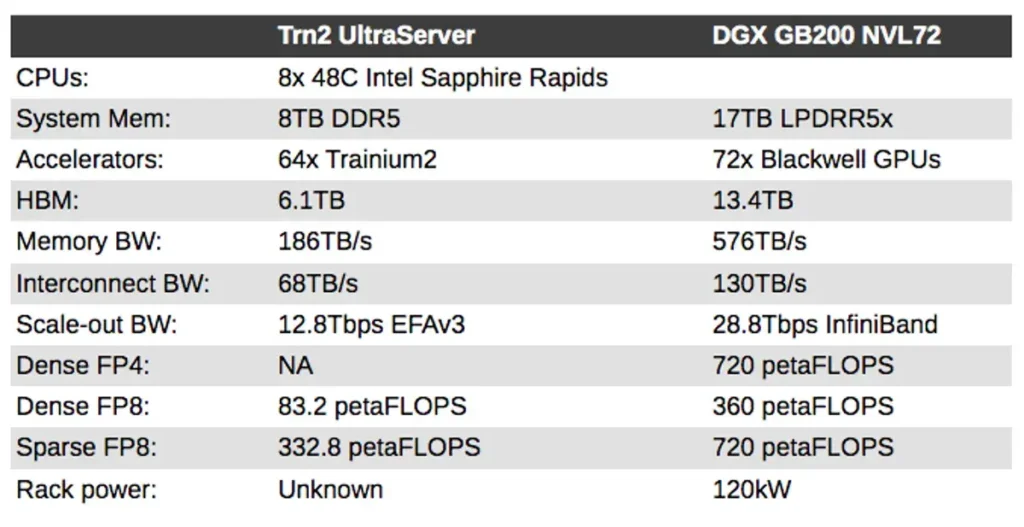
Como pueden ver, el NVL72 sigue siendo más rápido que el Trn2 de Amazon, pero, como señala Hutt, también hay que tener en cuenta el coste de ese cómputo. «Lo que nos piden los clientes no es ‘los chips más rápidos o los más complejos’. A los clientes les importa el rendimiento al menor coste, y por supuesto, también debe ser fácil de usar».
En definitiva, los clientes consumen Trainium como API de software en la nube, añadió.
Estos UltraServers son la unidad clave de cómputo que Amazon básicamente copiará y pegará a medida que desarrolla el «UltraCluster» completo del Proyecto Rainier.
Esta escalabilidad se logrará utilizando la red EFAv3 personalizada de Amazon, y nos han dicho que cada acelerador del clúster estará equipado con 200 Gbps de ancho de banda de red. Esto significa que cada UltraServer Trn2 tendrá 12,8 Tbps de conectividad, cortesía de las unidades de procesamiento de datos Nitro personalizadas de Annapurna, para mantener todos esos chips alimentados con datos de entrenamiento.
Esta tampoco es una red Ethernet típica. Amazon ha desarrollado una estructura personalizada que, según afirman, proporcionará decenas de petabits de ancho de banda (según entendemos, esto variará según la cantidad de UltraServers en el clúster) con menos de 10 microsegundos de latencia en toda la red.
Y Amazon está claramente preparado para unos gabinetes de red muy saturados. En la conferencia re:Invent del año pasado, el gigante de la nube detalló los esfuerzos que había realizado para evitar que sus gabinetes de red se convirtieran en un caos de cables de fibra óptica. Esto incluyó el desarrollo de una línea troncal de fibra óptica que comprime cientos de pares de fibras en lo que podría describirse como una cuerda fotónica.
Escalado horizontal.
Como mencionamos anteriormente, Amazon ha sido bastante impreciso sobre el tamaño final del Proyecto Rainier. Anteriormente se ha alardeado de que el sistema contendrá cientos de miles de chips Trainium2.
En su entrada de blog más reciente, afirmaba que «al conectar decenas de miles de estos UltraServers y dirigirlos al mismo problema, se obtiene el Proyecto Rainier».
Incluso tan solo 10.000 UltraServers equivaldrían a 640.000 aceleradores. Considerando que un clúster de un millón de aceleradores daría mucho más éxito a los titulares, asumiremos que los autores se referían a instancias Trn2, no a UltraServers.
Con seis millones de pies cuadrados de superficie, no esperamos que el espacio sea el factor limitante. Dicho esto, no esperamos que el campus de Amazon en Indiana se esté construyendo exclusivamente para el Proyecto Rainier. Debemos imaginar que gran parte de ese espacio estará ocupado por equipos de TI convencionales, como matrices de almacenamiento, conmutadores, CPU x86 y Graviton que ejecutan cargas de trabajo de virtualización y contenedores, y probablemente también una buena cantidad de GPU.
Amazon no ha revelado la cantidad exacta de energía que consumen sus chips, pero suponiendo que ronda los 500 vatios, estimamos que un conjunto de 256.000 aceleradores Tranium2 necesitaría entre 250 y 300 megavatios de potencia. Como referencia, esto equivale aproximadamente a la potencia de la supercomputadora Colossus de xAI, que contiene 200.000 GPU Hopper.
¿Se avecina un Proyecto Rainier 2.0?.
Hasta ahora, Amazon ha indicado que Trainium2 impulsará el Proyecto Rainier, pero con sus aceleradores de tercera generación a tan solo unos meses de su lanzamiento, no nos sorprendería descubrir que al menos algunos sitios web acaban utilizando el chip más nuevo y mucho más potente.
Anunciado por el equipo de Annapurna Labs en re:Invent el año pasado, el chip se fabricará en el nodo de proceso de 3 nm de TSMC y promete ofrecer una eficiencia un 40 % superior a la de la generación actual. Amazon también espera que sus UltraServers basados en Trainium3 ofrezcan aproximadamente cuatro veces el rendimiento de sus sistemas basados en Trn2.
Esto significa que podemos esperar que cada UltraServer Trn3 proporcione aproximadamente 332,8 petaFLOPS de FP8 denso o aproximadamente 1,33 exaFLOPS con la dispersión habilitada. Esto supone que Annapurna no esté utilizando tipos de datos de menor precisión como FP6 o FP4 para lograr estas mejoras de rendimiento. Pero más allá de estas métricas de rendimiento, los detalles siguen siendo escasos.
Sin duda, existen precedentes que respaldan un cambio de última hora.
Como recordarán, el Proyecto Ceiba de Amazon originalmente iba a utilizar los superchips Grace Hopper de Nvidia, pero finalmente optó por los aceleradores Blackwell, mucho más potentes.
Amazon solo puede hablar de chips y sistemas que ya se han lanzado, y aunque ya sabemos bastante sobre Trainium3, pasará un tiempo antes de que se puedan empezar a implementar cargas de trabajo en ellos.


