

Cuando la Casa Blanca anunció que los chips de inteligencia artificial H200 de Nvidia podrían venderse a «clientes aprobados» en China, a primera vista parecía un deshielo. El presidente Trump lo presentó públicamente como un acuerdo beneficioso para ambas partes: Nvidia recupera el acceso a un mercado crucial, mientras que el Tesoro estadounidense se queda con el 25% de los ingresos de China por esas ventas como parte del acuerdo.
Pero esto no es un regreso a la era anterior al control. Es algo nuevo: el control de las exportaciones convertido en una cabina de peaje. Nvidia puede vender un chip potente, pero no de vanguardia. El gobierno estadounidense obtiene un flujo de ingresos. Beijing obtiene una ventana estrecha y controlada para acceder a la computación estadounidense. Y todos comprenden que esa ventana puede volver a cerrarse.
Para comprender esto, hay que verlo desde la perspectiva de Beijing, no solo desde la de Washington. Las preguntas importantes ya no son «¿Puede China comprar H200?», sino:
- ¿Quién en China tiene realmente permiso para usarlo?
- ¿Para qué cargas de trabajo?
- ¿Y cuánto querrá realmente el país depender de él, dada la historia reciente?
Las respuestas apuntan a un mundo donde los chips estadounidenses siguen siendo tácticamente útiles para China, pero ya no son estructuralmente centrales.
Un precio, no un deshielo.
Los lineamientos básicos del acuerdo ya están claros.
Trump anunció que Nvidia puede exportar sus GPU H200 a clientes aprobados en China y otros mercados, sujeto a la revisión del Departamento de Comercio de EE.UU. y a un recorte del 25% de las ventas para el gobierno estadounidense.
Esto sigue a un acuerdo anterior, más pequeño, en torno al chip H20 de Nvidia, en el que, según se informó, se acordó una participación del 15% en los ingresos, pero las autoridades chinas posteriormente desalentaron las ventas, indicando que las empresas locales deberían priorizar los aceleradores nacionales.

Dos limitaciones definen la decisión sobre el H200:
- El H200 es potente, pero no es el producto estrella de Nvidia. La última línea Blackwell y los próximos chips Rubin siguen totalmente vedados para China.
- El acceso está mediado por ambas partes: las licencias de exportación estadounidenses están en vías de salida y la revisión regulatoria china está en vías de entrar.
Beijing ya ha manifestado su intención. Múltiples informes, que citan fuentes informadas sobre las opiniones de los reguladores, sugieren que China planea limitar el acceso al H200, incluso después de la aprobación de Washington, exigiendo aprobaciones adicionales o canalizando las compras a través de entidades designadas.
Esta es la realidad geopolítica fundamental:
- Estados Unidos ya no bloquea completamente los chips de IA de alta gama a China; mide el acceso y se lleva una parte.
- China ya no considera las GPU estadounidenses como una base predeterminada, sino como un complemento arriesgado y costoso.
La relación ha pasado de un comercio casi abierto a una interdependencia sujeta a impuestos.
¿Quién obtiene H200 en China y qué nos dice esto?.
Desde la perspectiva de la política china, la primera pregunta no es «¿Cuántos H200 podemos obtener?», sino «¿En qué parte del sistema nos atrevemos a colocarlos?».
La demanda de computación de IA en China se puede dividir aproximadamente en tres grupos:
- Gigantes de internet de primer nivel, proveedores de nube y laboratorios de IA líderes.
- Empresas de IA específicas de la industria en campos como la imagenología médica, las finanzas, la logística y la automatización industrial.
- Infraestructura crítica y entidades vinculadas al estado: operadores de telecomunicaciones, plataformas de nube estatales, infraestructura financiera, servicios públicos y centros de datos del sector público.
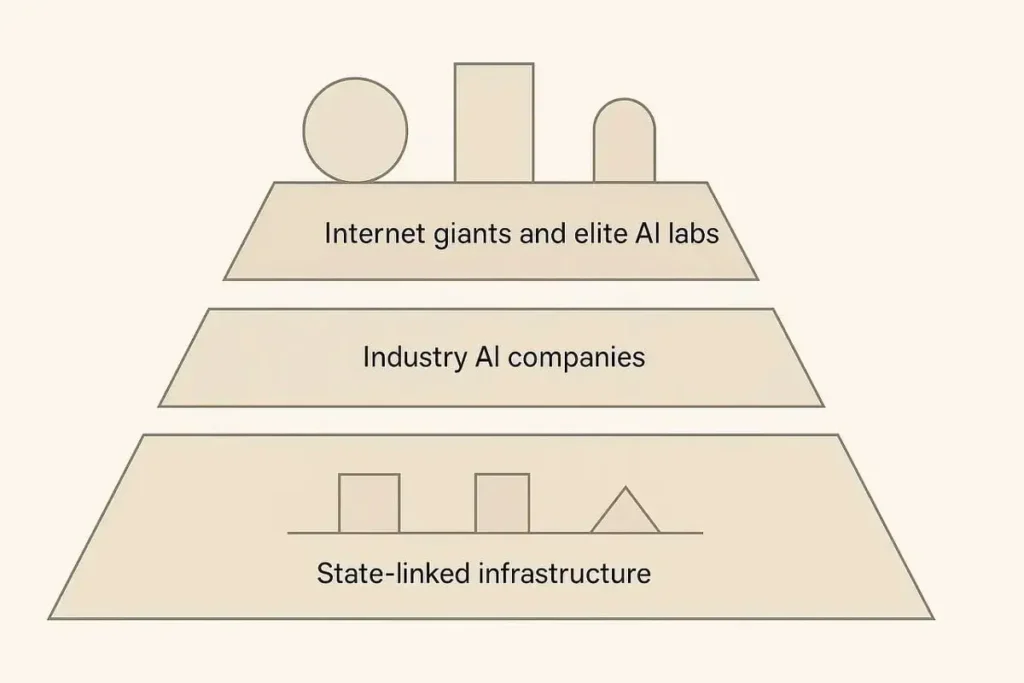
Es poco probable que el H200 penetre en las tres capas de forma uniforme. El patrón más plausible es:
- Uso concentrado en la cima, un puñado de gigantes y laboratorios de investigación de élite que realizan experimentos de vanguardia, modelos emblemáticos y proyectos orientados a la evaluación comparativa.
- Presencia limitada o simbólica en la zona intermedia, donde los aceleradores nacionales y las pilas de software optimizadas ya ofrecen un coste total de propiedad más predecible.
- Uso mínimo en la base, en sistemas críticos donde la continuidad del suministro, las garantías de seguridad y las señales políticas son más importantes que los picos de fracaso.
Este patrón se ajustaría a los incentivos de ambas partes. Washington puede afirmar que no ha «cortado» completamente el acceso a China. Beijing puede afirmar que aún tiene acceso a GPU de alto rendimiento. Sin embargo, la infraestructura central del estado digital chino sigue construida sobre hardware nacional o totalmente controlado.
Para los lectores globales acostumbrados a pensar en binarios simples —»acceso» o «sin acceso»—, este es el primer cambio de mentalidad:
- El acceso en China será estratificado, no uniforme.
- Cuanto más estratégica sea la carga de trabajo, más probable será que se ejecute en silicio nacional.
¿Qué cargas de trabajo ejecutará realmente H200?.
La segunda pregunta clave se refiere a las cargas de trabajo, no a las especificaciones principales.
Técnicamente, H200 es una mejora importante respecto a las piezas H20 comprometidas que se habían permitido en China a principios de 2025. Los analistas señalan que el H200 puede gestionar tanto el entrenamiento como la inferencia de forma eficiente, mientras que el H20 estaba limitado a la inferencia.
Pero su uso es más importante que su capacidad teórica. Existen cuatro categorías generales de carga de trabajo:
- Entrenamiento de modelos fronterizos: modelos lingüísticos o multimodales extremadamente extensos, nuevas arquitecturas, proyectos de investigación de alto riesgo.
- Ajuste de la industria y entrenamiento multitarea: adaptación de modelos base a dominios como finanzas, salud y manufactura.
- Inferencia a gran escala para productos de consumo y empresariales: chatbots, sistemas de recomendación, copilotos de oficina, productos SaaS.
- Implementaciones sensibles o reguladas: servicios gubernamentales, banca central, redes de telecomunicaciones, infraestructura crítica.
Es más probable que el H200 aparezca en la primera categoría, y en cierta medida en la segunda. Su función será ampliar las fronteras, alcanzar los puntos de referencia y reducir el tiempo de entrenamiento en modelos de vanguardia.

Para la inferencia diaria a escala, el cálculo es diferente. El coste de diseñar, implementar, alimentar y mantener grandes clústeres de inferencia se basa menos en el rendimiento máximo del chip y más en el coste total de propiedad, la compatibilidad del software y las garantías de suministro. Los aceleradores nacionales, incluso si son menos potentes, pueden ser competitivos o superiores en esta métrica.
Y en entornos regulados o adyacentes al gobierno, la lógica política es inflexible:
- El uso de chips nacionales puede ser técnicamente subóptimo hoy en día, pero políticamente sólido.
- El uso de H200 en el núcleo de estos sistemas revertiría años de esfuerzos para reducir la dependencia estratégica del hardware estadounidense.
Por ello, es probable que el H200 determine la I+D de vanguardia de China, no su infraestructura de IA para el mercado masivo.


