

La startup de chips de IA d-Matrix está incursionando en el escalado de racks con la introducción de sus tarjetas de E/S JetStream, diseñadas para permitir la distribución de modelos más grandes en múltiples servidores o incluso racks, minimizando al mismo tiempo los cuellos de botella en el rendimiento.
A simple vista, JetStream se presenta como una tarjeta de red PCIe 5.0 bastante estándar. Admite dos puertos a 200 Gb/s o un solo puerto a 400 Gb/s y opera sobre Ethernet estándar.
Según el director ejecutivo Sid Sheth, la startup consideró usar tarjetas de red (NIC) estándar de empresas como Nvidia, pero los investigadores de la compañía no estaban satisfechos con la latencia que podían lograr. En su lugar, optaron por diseñar su propia tarjeta de red utilizando una matriz de puertas programables en campo (FPGA) que consume aproximadamente 150 W. Aún más importante, d-Matrix afirma haber logrado reducir la latencia de la red a tan solo dos microsegundos.
Dos de estas tarjetas de red (NIC) están diseñadas para combinarse con hasta ocho aceleradores de IA Corsair de 600 vatios del fabricante de chips, en una topología similar a la siguiente.

Los ASIC personalizados tampoco se quedan atrás, ya que cada tarjeta es capaz de generar 2,4 petaFLOPS al utilizar el tipo de datos MXINT8 o 9,6 petaFLOPS al utilizar el tipo MXINT4, de menor precisión.
La jerarquía de memoria de d-Matrix combina una gran cantidad de SRAM increíblemente rápida con memoria LPDDR5 mucho más lenta, pero de mayor capacidad, la misma que encontrarías en un portátil de alta gama.

Cada tarjeta Corsair contiene 2 GB de SRAM con una velocidad de 150 TB/s, junto con 256 GB de LPDDR5 con una capacidad de 400 GB/s. Para poner estas cifras en perspectiva, una sola Nvidia B200 ofrece 180 GB de HBM3e y 8 TB/s de ancho de banda.
Como recordatorio, la inferencia de IA suele ser una carga de trabajo con limitaciones de ancho de banda, lo que significa que cuanto más rápida sea la memoria, más rápido generará tokens.
«Dependiendo de la compensación que el cliente desee hacer entre velocidad y costo, puede elegir el tipo de memoria en la que desea ejecutar los modelos», afirmó Sheth.
Dos terabytes de LPDDR5 por nodo ofrecen suficiente capacidad para ejecutar modelos de varios billones de parámetros con una precisión de 4 bits, pero con 3,2 TB/s de ancho de banda de memoria agregado, no será rápido.
Para obtener el máximo rendimiento, d-Matrix sugiere ejecutar los modelos completamente en SRAM. Sin embargo, con 16 GB de memoria en chip ultrarrápida por nodo, quienes deseen ejecutar modelos más grandes y con mayor capacidad necesitarán muchos sistemas. Con ocho nodos por rack, d-Matrix estima que puede ejecutar modelos de hasta unos 200 mil millones de parámetros con una precisión MXINT4, con la posibilidad de ejecutar modelos más grandes al escalar en varios racks.

Y esto es precisamente lo que las tarjetas de E/S d-Matrix JetStream están diseñadas para permitir. d-Matrix utiliza una combinación de paralelismo tensorial, experto, de datos y de pipeline para maximizar el rendimiento de estos clústeres de cómputo a escala de rack.
Con tan solo 800 Gb/s de ancho de banda agregado provenientes de las dos NIC JetStream en estos sistemas, d-Matrix parece estar siguiendo una estrategia similar a la observada en sistemas GPU hasta la fecha: utiliza paralelismo tensorial para distribuir las ponderaciones del modelo y la carga de trabajo computacional entre los ocho aceleradores del nodo y una combinación de paralelismo de pipeline o experto para escalar dicho cómputo en múltiples nodos o racks.
El resultado es una especie de cadena de montaje de inferencia, donde el modelo se divide en fragmentos que se procesan secuencialmente, un nodo a la vez.
Si esto le suena familiar, así es como startups de chips de la competencia como Groq (que no debe confundirse con LLM Grok, obsesionado con la autoritarismo, de xAI) o Cerebras han logrado crear servicios de inferencia de altísimo rendimiento sin depender de una memoria de gran ancho de banda.
Si pensaba que usar 64 aceleradores de IA para ejecutar un modelo de 200 mil millones de parámetros era excesivo, Groq utilizó 576 de sus unidades de procesamiento de lenguaje (LPU) para ejecutar Llama 2 70B, aunque con mayor precisión.
A pesar de la complejidad adicional de distribuir modelos entre tantos aceleradores, mantenerlos en SRAM tiene sus ventajas. d-Matrix afirma que sus chips Corsair pueden alcanzar latencias de generación de tan solo 2 ms por token en modelos como Llama 3.1 70B. Si a esto le sumamos decodificación especulativa, como ha hecho Cerebras con sus propios chips con SRAM, no nos sorprendería ver que ese rendimiento se duplica o triplica.
Con JetStream, d-Matrix está mejor posicionada para competir en este ámbito. Sin embargo, la falta de ancho de banda de interconexión que ofrecen las tarjetas de red (NIC) implica que el esfuerzo de la compañía por escalar en rack se limita actualmente a escalar horizontalmente las arquitecturas de escalado vertical a las que Nvidia y AMD están en transición con sus sistemas de rack NVL72 y Helios. Este último, como se indica, no se lanzará hasta el próximo año como muy pronto.
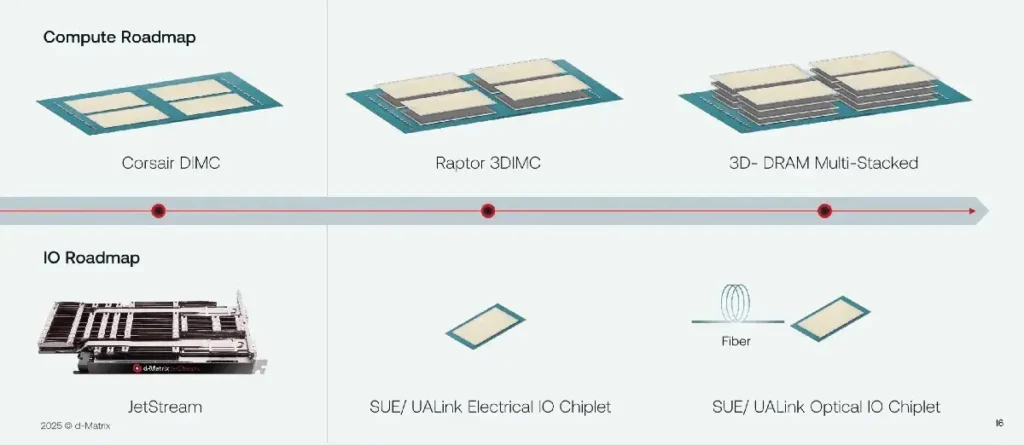
Sin embargo, d-Matrix no tardará en unirse a ellos con su familia de aceleradores Raptor de próxima generación, que, además de SRAM apilada en 3D para una mayor capacidad, utilizará un chiplet de E/S eléctrico integrado para lograr una red a escala de rack similar a la NVLink de Nvidia.
Si bien aún queda mucho camino por recorrer, la hoja de ruta de d-Matrix prevé la transición a un chiplet de E/S óptico, lo que permitirá que la arquitectura escale en múltiples racks o incluso en filas de sistemas.
Según d-Matrix, JetStream actualmente está realizando muestreos para clientes y se espera que la producción aumente antes de fin de año.


